

Por que Quantum Machine Learning?
É muito comum as pessoas ficarem impressionadas com o poder que os computadores, smartphones e tecnologias semelhantes possuem. Por exemplo, ao digitar uma frase no google, rapidamente o sistema a completa de tal forma que a maioria das pessoas talvez se perguntem: Como se consegue descobrir que era isso que eu queria digitar? – É normal pensar que a tecnologia está “lendo” nossos pensamentos, como no filme “Harry Potter e a Ordem da Fênix”, quando o protagonista Snape consegue ler os pensamentos de Harry Potter (risos)-

As tecnologias conseguem executar algumas tarefas humanas de forma relativamente rápida, dentre elas, prever se o tempo estará bom ou ruim, indicar uma música baseado nos gostos musicais do usuário, dirigir um carro, prever falhas em determinado equipamento e produzir textos, como o sistema GPT-3 (Generative Pre-trained Transformer 3) publicado em 2020. Calma! Esses sistemas não vão dominar o mundo – Ainda não (risos) – É que todas essas tecnologias de inovação se resumem a um método de análise de dados que automatiza a construção de modelos analíticos chamado Aprendizado de Máquina – Dificultou um pouco? Se dificultou, vou tentar facilitar – Algumas teorias afirmam que o ser humano aprende a falar a linguagem nativa por ouvi-la muitas vezes. Uma criança aprende que não pode comer certas coisas, porque muitas vezes alguém a ensina que aquela coisa não pode comer. Salvo algumas exceções, as pessoas conseguem diferenciar vários objetos pelas cores porque elas conseguem identificar e aprender esses padrões, o que é amarelo é amarelo, o que é verde é verde e, assim por diante.
Observe que os exemplos citados transmitem a ideia de que certos conhecimentos são empíricos. No começo da vida, aprendemos a contextualizar determinadas palavras corretamente, porque compreendemos a linguagem verbal e comportamental das pessoas. Isso pode ser utilizado para associarmos ao aprendizado de máquina, que é um ramo da inteligência artificial no qual os sistemas podem aprender com os dados, identificar pradrões e tomar decisões, tendo o mínimo de intervenção humana. No caso da criança que aprende que não pode comer certas coisas, os dados são divididos em dois grupos: coisas comestíveis e coisas não comestíveis. O modo como a criança aprende é através da abordagem do “Não meta isso na boca, isso não é comestível”.
Até aqui tudo ok! Perceba que o mundo real nos trazem dados fundamentais para o aprendizado. Mas, no caso das máquinas, como conseguem absorver o conhecimento através destes dados? A resposta para essa pergunta pode ser: os tão falados algoritmos de aprendizagem de máquina. De acordo com (GARRETT, 2020), estes, caracteriza um conjunto de etapas que um software qualquer precisa realizar para chegar a um resultado. Existem vários tipos de algoritmos de aprendizado de máquina, mas todos eles seguem etapas comuns, conforme (ZICKERT, 2021) essas são:
- Representação – Arquitetura interna que o algoritmo usa para representar o conhecimento. Dentre estas temos: Árvores de decisão, Redes Neurais, Máquinas de Vetores Suporte;
- Avaliação – Se resume em encontrar uma função matemática para avaliar parametrizações para os algoritmos candidatos;
- Otimização – Descreve a forma de gerar parametrizações do algoritmo candidato.
A etapa 1 vai medir o quão adequada é a solução para resolver o problema. Ou seja, dentre as arquiteturas de aprendezado de máquina existentes qual é a mais adequada para resolver o problema? A arquitetura especifica os valores dos parâmetros que vão manter a representação do conhecimento.
Utilizar muitos parâmetros não é sinônimo de “melhor arquitetura”. Por exemplo, a função linear utiliza poucos parâmetros para resolver problemas simples. Por outro lado, se o problema for complexo, resolvê-lo com poucos parâmetros não é indicado.
A quantidade de parâmetros vai definir se precisamos de muitos exemplos ou poucos exemplos para treinar o nosso modelo. – Mas, como assim, treiná-lo? Seria igual a um time de futebol? – Sim, basicamente é isso! A medida que um time treina, aumenta a probabilidade de fazer um bom jogo. Da mesma forma é o treino do algoritmo. Nesta etapa, precisamos repetir os mesmos passos para a máquina aprender. Esse processo é denominado: Processo Iterativo. Dependendo do tipo de algoritmo e do problema, essa iteratividade pode demorar muito e não chegar a uma resposta, em virtude da quantidade de parâmetros. É importante que essa quantidade seja proporcional a complexidade do problema que está relacionada ao número de exemplos (instâncias) de dados que a máquina possui para ser treinada e consequentemente ao tempo de execução do algoritmo.
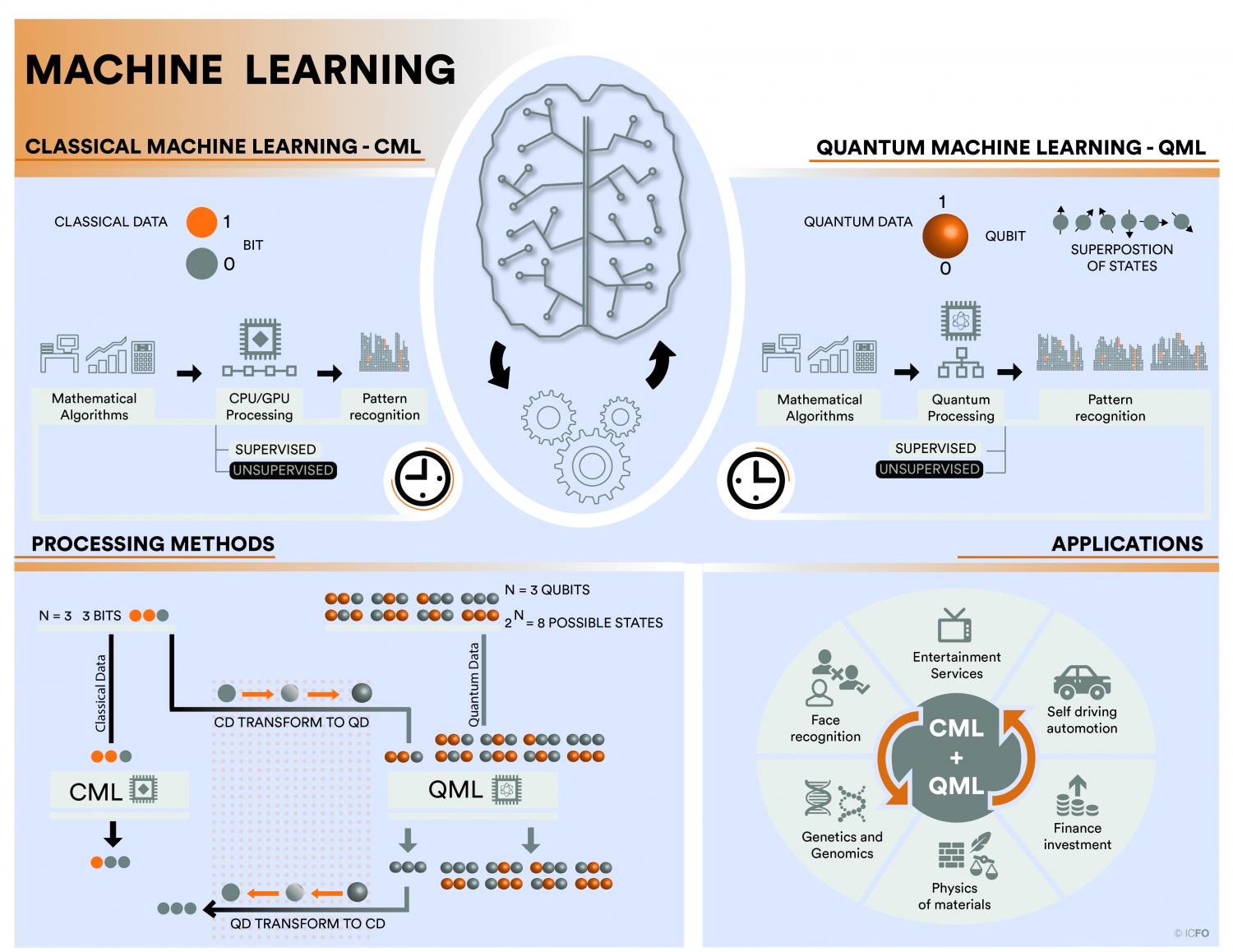
O processamento de informação dos computadores clássicos, na maioria dos casos, é sequencial e isso causa demora no término de execução de alguns algoritmos; outro problema é o armazenamento de informação que o computador precisa para executar um algoritmo de aprendizado de máquina. De acordo com (SCHULD, 2015) o volume de dados globais cresce em torno de 20% anualmente, e está na ordem de centenas de exabytes – Número 1 seguido de 18 zeros. Considerando a lei de Gordon Earle Moore, presidente da Intel, a quantidade de transistores – semicondutor responsável pela qualidade de um microprocessador que está relacionada ao processamento de informação – teria de dobrar a cada ano para conseguirmos um crescimento exponencial na inovação dos meios tecnológicos. Mas, existe uma limitação dimensional dos microchips utilizados para alocar esses transistores – Será que chegará uma hora que não conseguiremos mais processar toda essa informação que vem crescendo a cada ano? – Mantenham a calma novamente! Pois já se buscam alternativas, visando solucionar este problema. Uma delas é a Computação Quântica!
Físicos já demonstraram, nas últimas décadas, que sistemas quânticos podem ter um poder maior no processamento de informação (SCHULD, 2015). Diferentemente, dos sistemas clássicos que codificam informação em bits que assumem somente dois estados ‘0’ ou ‘1’, os sistemas quânticos codificam a informação em bits quânticos ou qubits. Esse tipo de bit é um sistema físico que assume dois estados, como os elétrons do átomo de hidrogênio, que pode estar no estado fundamental ou no primeiro estado excitado de energia, ou ainda assumir qualquer superposição desses dois estados anteriores. Assim, além de codificar a informação em estados ‘0’ ou ‘1’, também se consegue codificar em uma combinação linear de estados, ‘0’ e ‘1’. Como os bits quânticos são sistemas quânticos, eles obedecem três propriedades fundamentais da mecânica quântica:
- Emaranhamento – Propriedade com duas partículas quânticas que se correlacionam fortemente, independente das distâncias entre elas;
- Interferência – Este é o fenômeno que nos permitirá direcionar os sistemas quânticos para o estado desejado. Caminhos que levam a respostas erradas interferem destrutivamente, cancelando mutuamente. Por outro lado, caminhos que levam às respostas corretas se interferem, construtivamente, reforçando uma a outra;
- Superposição – Sistemas quânticos podem existir em múltiplos estados ao mesmo tempo.
O que torna a computação quântica poderosa são essas propriedades que possibilitam executar algoritmos com uma complexidade computacional diferente dos executados com a computação clássica. – Mas pera aí… O que significa complexidade? – A complexidade mede o esforço computacional para executar determinado algoritmo. Por exemplo, a soma de dois números:
8+6 = 14
18 + 06 = 24
418 + 406 = 824
Observe que, quanto maior o tamanho do número, mais operações precisam ser realizadas.
–> 8 + 6 –>1 operação
–> 18 + 06 –>2 operações (8+6, 1+1+0)
–> 418 +406 –> 3 Operações (8+6, 1+1+0, 4+4)
O esforço computacional é a quantidade de operações a serem resolvidas. Como essa quantidade é igual a quantidade de algarismos que as parcelas possuem (tamanho do número), dizemos que a complexidade é linear e representamos por O(n), onde n é o esforço computacional ou tamanho do problema necessário para executar o algoritmo. O processo de multiplicar dois números tem uma complexidade O( n²), onde n também é o esforço computacional ou o tamanho do problema. Assim, o esforço de multiplicar é maior que o de somar. Existem vários tipos de complexidades como mostra a Figura 1.

Fonte: (ZICKERT, 2021)
Segundo (ZICKERT, 2021), a computação quântica é uma tecnologia emergente e potente, pois promete resolver certos problemas que envolvem cálculos matemáticos em uma complexidade reduzida em comparação ao clássico – O que seria essa complexidade reduzida? – Por exemplo, a complexidade de um algoritmo clássico para resolver um problema de fatorar um número em fatores primos é exponencial, em contrapartida, o algoritmo de Shor, que utiliza a computação quântica para executar a mesma tarefa, leva um tempo polinomial. Isso quer dizer que o esforço computacional para resolver o problema de fatorar números primos é menor no caso quântico que no clássico. Agora, suponha que eu tenha um problema de tamanho n = 1000. Se quisermos executá-lo em uma máquina que tenha um tempo polinomial, n3 e em seguida, em uma máquina que tenha um tempo exponencial 2n, este problema teria uma complexidade de 1000³ = 1 bilhão na máquina de tempo polinomial e na máquina de tempo exponencial, esse problema teria uma complexidade de 21000. Esse último valor é um número maior que a quantidade de átomos do universo. Portanto, algoritmos com tempo polinomial são ditos tratáveis na prática e esse grupo de problemas é denominado problemas tipo P.
Explorar o potencial da computação quântica para otimizar algoritmos de Machine Learning clássicos é bastante promissora e daí surge o conceito de Quantum Machine Learning que se resume na ideia de integrar algoritmos quânticos em programas de aprendizagem de máquina, melhorando e muitas vezes agilizando as técnicas clássicas de aprendizado de máquina.
Cenário atual da Quantum Machine Learning – Era NISQ
Como vimos anteriormente, a Computação Quântica é uma forma diferente de se fazer computação com potencial de reduzir a complexidade de certos algoritmos de aprendizado de máquina, influenciando no tempo de processamento e na forma de armazenamento de dados. Por outro lado, ao contrário de computadores clássicos, os dispositivos quânticos precisam ser muito precisos devendo manter um estado quase contínuo. Como os algoritmos quânticos baseiam-se em manipulações específicas de parâmetros continuamente variáveis os erros podem ser arbitrariamente pequenos e impossíveis de detectar, mas ainda assim, seus efeitos podem se acumular arruinando cálculos.
Os estados quânticos são frágeis e portanto, muito vulnerável ao ruído proveniente do ambiente em que o quibit está inserido. Estes ruídos podem surgir da eletrônica de controle, do calor, de impurezas no próprio material do computador quântico ou da temperatura externa do ambiente (dispositivos que utilizam uma arquitetura de hardware baseada em supercondução, a temperatura pode causar vibrações nos bits quânticos e causando sérios erros de computação que podem ser difíceis de corrigir, resultando em erros de cálculo )- O computador da IBM, por exemplo, é mantido em uma sala refrigerada numa temperatura de 15 milikelvin ~ -273.135 ºC com o objetivo de minimizar as vibrações e consequentemente os erros de cálculo. Para conseguirmos resolver problemas intratáveis na computação clássica, precisaríamos de dispositivos com milhões de bits quânticos a fim de corrigirmos os erros resultantes desses ruídos. Os dispositivos quânticos atuais, possuem entre 20 a algumas centenas de qubits. Mesmo esses pequenos dispositivos sendo ruidosos, já se consegue resolver problemas intratáveis na computação clássica. Essa era é conhecida como era NISQ – Noisy Intermediate-Scale Quantum.
Atualmente, com esses pequenos dispositivos, já se arquiteta algoritmos denominados algoritmos NISQ. Dentre eles, os algoritmos variacionais (VQE) ou o algoritmo de Otimização aproximada quântica (QAOA) que ambos são algoritmos híbridos que usam dispositivos NISQ para serem executados, implementando algumas partes do algoritmo em processadores clássicos usuais para reduzir o esforço de determinados cálculos. Esses algoritmos ajudaram a recuperar resultados conhecidos em química quântica e algumas aplicações foram sugeridas em física, ciência de materiais, biologia, finanças, ciência de dados, criptografia e manutenção preditiva.
O trabalho intitulado Quantum Machine Learning: A Review and Current Status, escrito por (Mishra et al., 2021), contextualizou os diferentes tipos de atividades que podemos utilizar na área de Quantum Machine Learning, dentre elas temos:
Técnicas De Cluesterização – Utiliza o algoritmo quântico de Lloyd para resolver o problema de agrupamento k-means através de procedimentos repetitivos para obter a distância do ponto até o centroide do cluster. Esse algoritmo acelera o processo em comparação com o algoritmo clássico. Para um espaço dimensional N, ele demanda tempo O(Mlog(MN)) para executar a etapa do algoritmo quântico;

(Fonte :https://media2.giphy.com/media/12vVAGkaqHUqCQ/giphy.gif)
Rede Neural Quântica – Uma técnica de aprendizagem supervisionada profunda para treinar a máquina com o intuito de classificar dados, reconhecer padrões ou imagen. É uma rede do tipo feed-forward. O princípio básico é projetar os circuitos com qubits (análogos aos neurônios) e portas de rotação (análogas aos pesos usados nas redes clássicas). A rede quântica aprende com um conjunto de exemplos de treinamento. Cada string vem com um valor de rótulo. A função da rede é obter o valor do rótulo do conjunto fornecidos e minimizar o desvio do valor obtido com o verdadeiro. O principal ponto é obter o parâmetro de treinamento que forneça o erro mínimo. O parâmetro de treinamento é atualizado a cada iteração. A minimização de erros é feita pela técnica de retropropagação baseada no princípio do gradiente descendente;

Fonte: ( Disponível em: https://argmax.ai/blog/layerwise-learning-for-quantum-neural-networks/)
Árvore de Decisão Quântica – As Árvores de decisão emprega estados quânticos para criar classificadores. A estrutura é baseada em árvores, existe um nó inicial chamado raiz sem nenhuma entrada e a partir desse nó raiz existem arestas que se ligam a outros nós denominados folhas ou também chamados de nós internos. Nessa estrutura, a resposta a uma pergunta é classificada à medida que descemos. Cada nó contém uma função de decisão que vai definir a direção do movimento do vetor de entrada ao longo dos ramos e folhas. A árvore de decisão quântica aprende com os dados de treinamento: cada nó basicamente divide o conjunto de dados de treinamento em subconjuntos com base na função discreta. Cada folha da árvore de decisão é atribuída a uma classe de saída com base nos atributos de destino desejados. Assim, a árvore de decisão quântica classifica os dados entre seus diferentes componentes: folhas e nós raiz/internos (que contêm decisões baseadas em qual de seus nós filhos é percorrido para classificação posterior).

O aprendizado de máquina quântico ainda é bastante explorado. As limitações de Hardware ainda é um fator limitante para se conseguir novos resultados vantajosos que a computação quântica pode trazer. Mas já conseguimos, mesmo com dispositivos relativamente pequenos, conseguir realizar tarefas nas quais a computação clássica sozinha não conseguiria. Em virtude disso, se explora muito os algoritmos híbridos (quântico/clássico) em diversas áreas:
- Engenharia Aeroespacial: Particionamento de malha ideal para elementos finitos;
- Biologia: Reconstrução da filogenia;
- Engenharia Química: Síntese de rede de trocadores de calor;
- Química: Dobramento de Proteínas;
- Engenharia Civil: Equilíbrio do fluxo de tráfego urbano;
- Economia: Computação de arbitragem nos mercados financeiros com fricção;
- Engenharia elétrica: Layout VLSI;
- Engenharia Ambiental: Posicionamento ideal de sensores de contaminantes;
- Engenharia financeira: Portfólios;
- Teoria de jogos: Equilíbrio de Nash que maximiza o bem-estar social;
- Engenharia Mecânica: Estrutura de turbulência em escoamento cisalhados;
- Medicina: Reconstruindo a forma 3D do angiocardiograma biplano;
- Pesquisa Operacional: Problema do Caixeiro Viajante;
- Física: Função de partição do modelo 3d Ising;
- Política: Poder de voto Shapley-Shubik;
- Recreação : Versões de Sudoku, Damas, Campo Minado, Tetris;
- Estatística: Design experimental ideal.
Aprendizado de máquina quântico promete ser uma ótima alternativa para conseguirmos armazenar e utilizar a quantidade de dados que existem e irão existir nos próximos anos. As pesquisas em melhora de hardware quântico estão ocorrendo em desenvolvimento acelerado para utilizarmos esses dispositivos para obtermos um poder de processamento mais eficiente em tarefas de aprendizagem de máquina.

